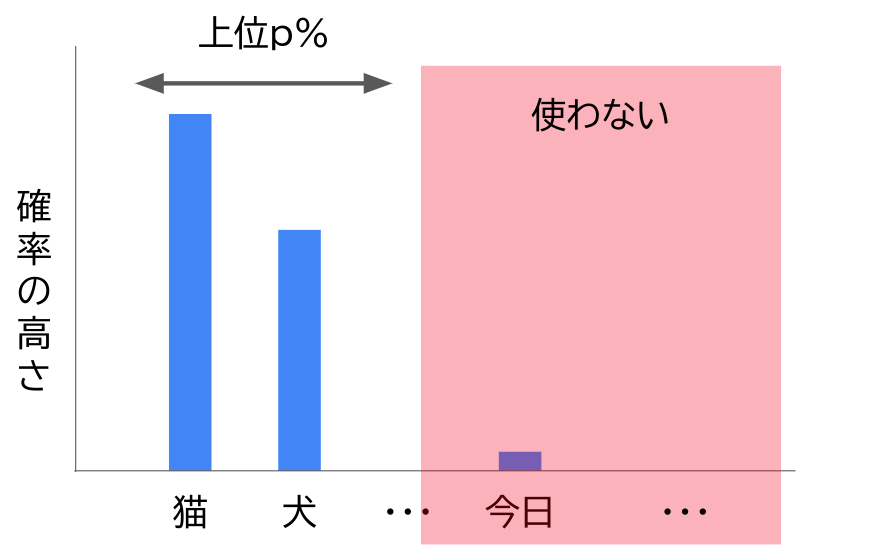
Top Pは Nucleus Sampling(Top-p Sampling) という手法で使われるパラメータです。確率分布から語を選ぶ時、最も高い語からの累積確率を数えて上位一定割合の語のみを選択対象にし、それ以下は足切りをします。
参考資料:https://techblog.a-tm.co.jp/entry/2023/04/24/181232
Top Pのデフォルト値は1.0が使われる事が多いと思います。1.0というのはすべての語を選択対象とし足切りをしないということ、つまりNucleus Samplingをしないということです。
言語モデルによってはTop Pを下げることで、あり得ないような出力をすることが減ります。
逆に、Top Pを下げすぎると、表現の幅が狭く単調な文章になります。